fsteeg.com
| notes
![]() | tags
| tags
∞ /notes/why-lod-needs-applications-and-libraries-need-apis | 2015-12-07 | programming swib lobid web libraries nwbib
Why LOD needs applications, and libraries need APIs
Cross-posted to: https://fsteeg.wordpress.com/2015/12/07/why-lod-needs-applications-and-libraries-need-apis/
This post is based on a talk I gave at SWIB15 on November 24 titled "LOD for applications: using the Lobid API". I recently stumbled upon a poster by the American Library Association from 1925, which advertises library work as "the profession on which all other professions and occupations depend": Source: http://imagesearchnew.library.illinois.edu/cdm/singleitem/collection/alaposters/id/23/rec/2
I'm sure that anyone who does library work kind of likes that sentiment, I certainly do. At the same time it makes you wonder how true that statement actually is. Even back then. For instance my grandfather, who was a baker, I don't think he actually depended on library work.
But even more, it makes you wonder how true that is today. I don't have an answer to that, but to the extend that it is true today, there's something else involved, and that's software.
Because today software is a thing on which every profession and occupation depends. Well, as the statement about library work wasn't quite true even in 1925, the statement about software isn't quite true today. Not all professions and occupations actually depend on software. But there is one profession that certainly does, and that's library work.
Because "libraries are software". The services that libraries provide are provided directly or indirectly through software.
Source: http://imagesearchnew.library.illinois.edu/cdm/singleitem/collection/alaposters/id/23/rec/2
I'm sure that anyone who does library work kind of likes that sentiment, I certainly do. At the same time it makes you wonder how true that statement actually is. Even back then. For instance my grandfather, who was a baker, I don't think he actually depended on library work.
But even more, it makes you wonder how true that is today. I don't have an answer to that, but to the extend that it is true today, there's something else involved, and that's software.
Because today software is a thing on which every profession and occupation depends. Well, as the statement about library work wasn't quite true even in 1925, the statement about software isn't quite true today. Not all professions and occupations actually depend on software. But there is one profession that certainly does, and that's library work.
Because "libraries are software". The services that libraries provide are provided directly or indirectly through software.
This post is based on a talk titled LOD (Linked Open Data) for applications: using the Lobid API (Application Programming Interface). So why would you want to use an API? Well, because LOD for applications means building software. And APIs make software development manageable. They allow us to build modular software, with stable applications that don't have to change when other parts of the software change. At the same time, they allow us to have flexible data sources that can change without requiring changes in the applications. Lets take a look at what that means in the case of the Lobid API. The Lobid API provides access to authority data from different sources in different formats, to geodata from Wikidata, and to bibliographic title data from the hbz union catalogue. Applications access this data through the API:"Libraries are Software" by @codyh — Good short essay for dev and non-dev librarians http://t.co/Y9YLmTaZj0 pic.twitter.com/iVGKFaBql8
— Tim Spalding (@librarythingtim) September 17, 2015
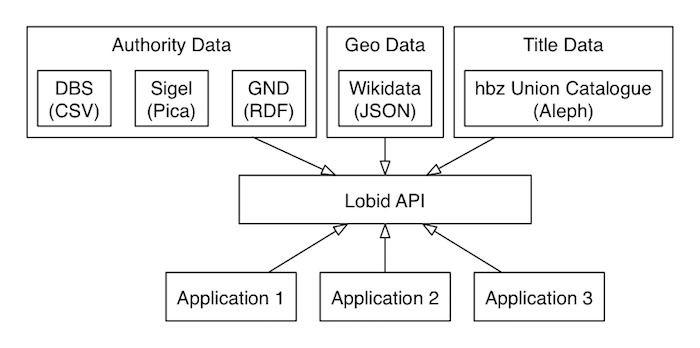 That way, the API decouples the applications from the concrete data sources, formats, and systems, which can change without requiring the applications to change at the same time.
That way, the API decouples the applications from the concrete data sources, formats, and systems, which can change without requiring the applications to change at the same time.
Using APIs
So the talk mentioned above is subtitled Using the Lobid API. Now what does that even mean, to use an API? In the case of a Web API, it basically means opening URLs. So it's just like opening a Web site, but what we want to get back is structured data: http://beta.lobid.org/organisations/search?q=hbz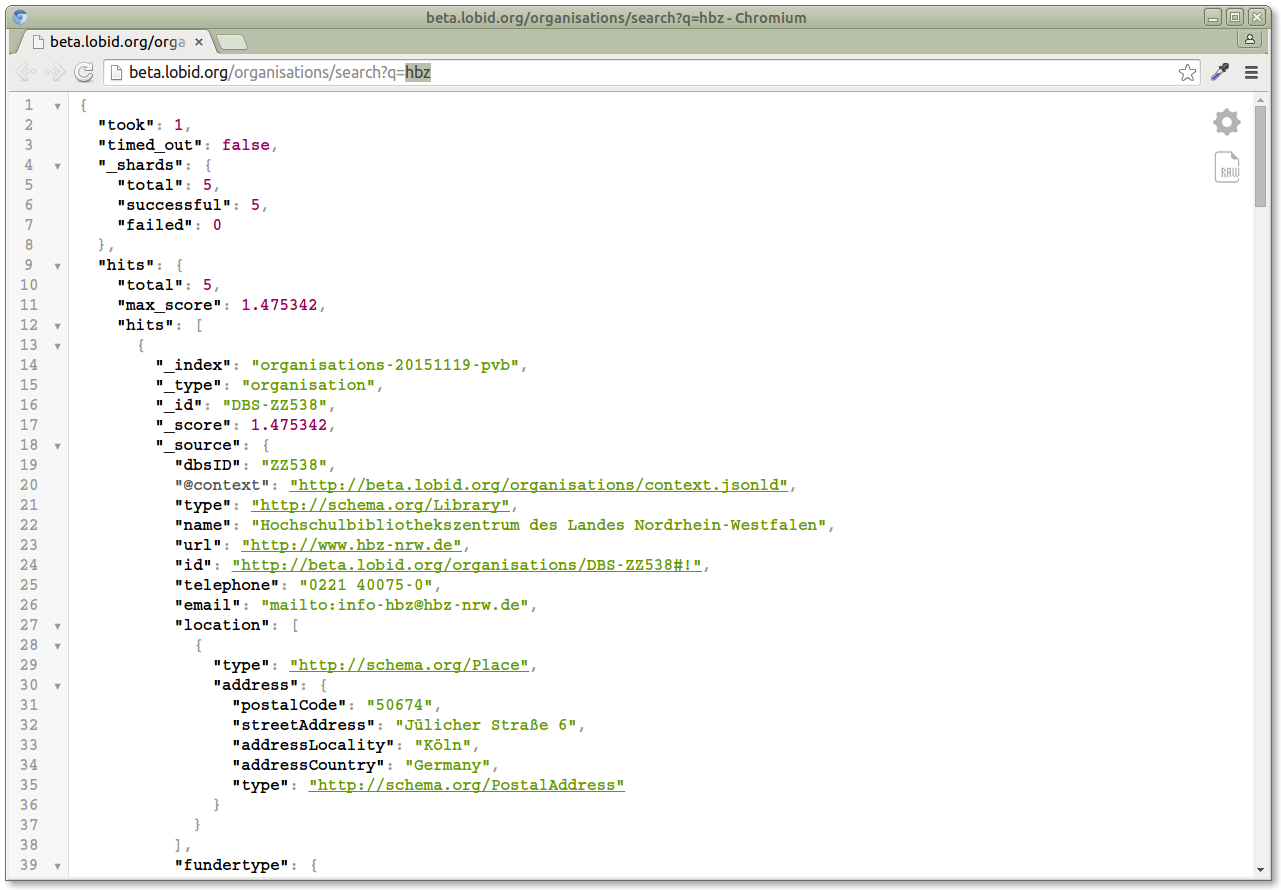 This sample queries our API for organisations containing "hbz". Now if we change the URL in the browser address bar to search for something else, like "zbw", we get a different result:
http://beta.lobid.org/organisations/search?q=zbw
This sample queries our API for organisations containing "hbz". Now if we change the URL in the browser address bar to search for something else, like "zbw", we get a different result:
http://beta.lobid.org/organisations/search?q=zbw
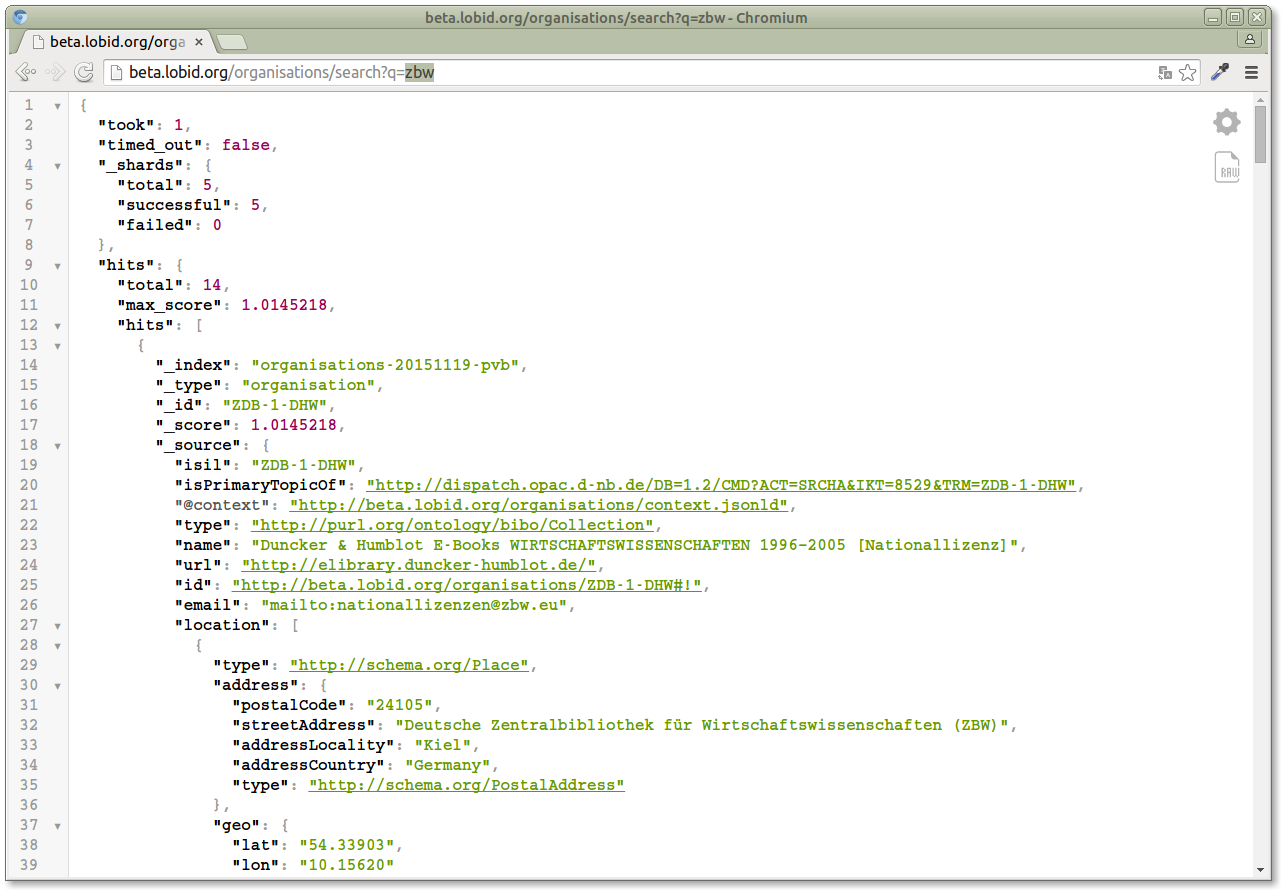 We're using the API.
We're using the API.
Application: bulk downloads
The idea of an API is that we can use the same URLs we opened in a browser in different ways. For instance, we can call them from the command line, to get bulk downloads:curl -H "Accept: application/ld+json" -H "Accept-Encoding: gzip""http://lobid.org/resource?owner=DE-6&scroll=true""http://lobid.org/resource?subject=4055382-6&scroll=20151023"> "resources-4055382-20151023.gz"curl -H "Accept: application/ld+json" -H "Accept-Encoding: gzip" "http://lobid.org/resource?subject=4055382-6&scroll=20151023" > "resources-4055382-20151023.gz"
So what we get from this is local data, ready for offline usage, but still retrieved from an API. There is no contradiction between local data dumps and APIs, an API is just a way to deliver data.
Application: answer a single question
Now let's take a look at a concrete application. Say we want to answer a single question, like "How many libraries are there in Germany?". Is it 10.000, which is kind of the traditional answer:Or is it more like 20.000, as an initial query to our API suggested:.@fsteeg "10.200 [Bibliotheken] gibt es insgesamt". Sind eher doppelt so viel, wenn man die Pfarrbibliotheken dazu zählt.
— Adrian Pohl (@acka47) May 29, 2015
So let's take a look at how we can answer that question by using the Lobid API. First lets take a look at a single organisation ("DE-206H") in our API. This organisation contains a "type" field which specifies that this is a library. So this is the first field we'll be using, since we want to query for all libraries in Germany. The organisation also contains a nested "addressCountry" field: http://beta.lobid.org/organisations/DE-206HIn Deutschland gibt es 19.347 Bibliotheken http://t.co/qPcY3Kh7o7 . Datenquelle: dbs und ZDB-Sigeldatei /via @lobidOrg API
— dr0ide (@dr0ide) June 10, 2015
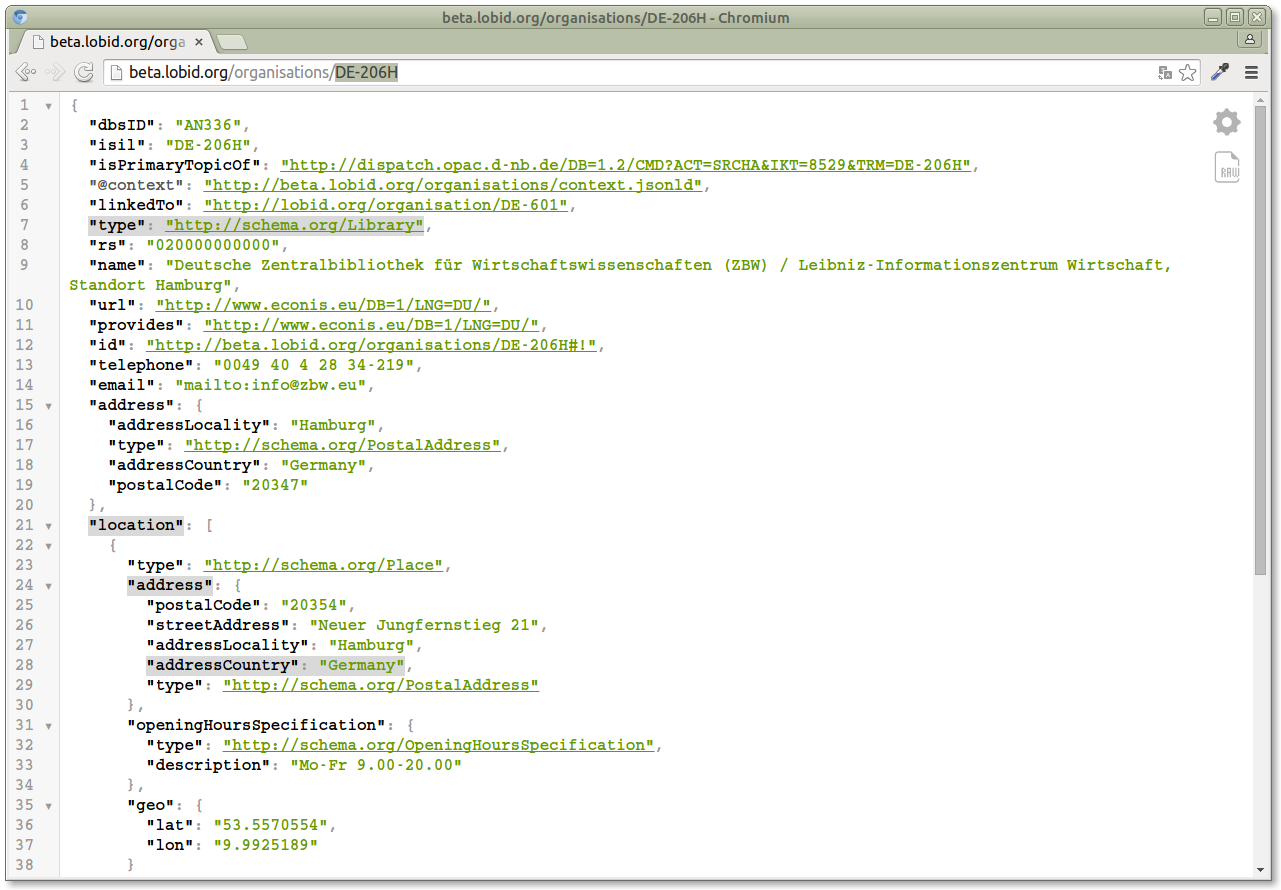 The "addressCountry" field is nested in an "address" field, which itself is nested in a "location" field. We can express the path to this nested field as "location.address.addressCountry".
With these two fields, we can now create a query that expresses that we're looking for organisations with "type:Library AND location.address.addressCountry:Germany" (the + in the address bar are encoded spaces). In the response, we have a "hits.total" field with the answer to our question:
http://beta.lobid.org/organisations/search?q=type:Library+AND+location.address.addressCountry:Germany
The "addressCountry" field is nested in an "address" field, which itself is nested in a "location" field. We can express the path to this nested field as "location.address.addressCountry".
With these two fields, we can now create a query that expresses that we're looking for organisations with "type:Library AND location.address.addressCountry:Germany" (the + in the address bar are encoded spaces). In the response, we have a "hits.total" field with the answer to our question:
http://beta.lobid.org/organisations/search?q=type:Library+AND+location.address.addressCountry:Germany
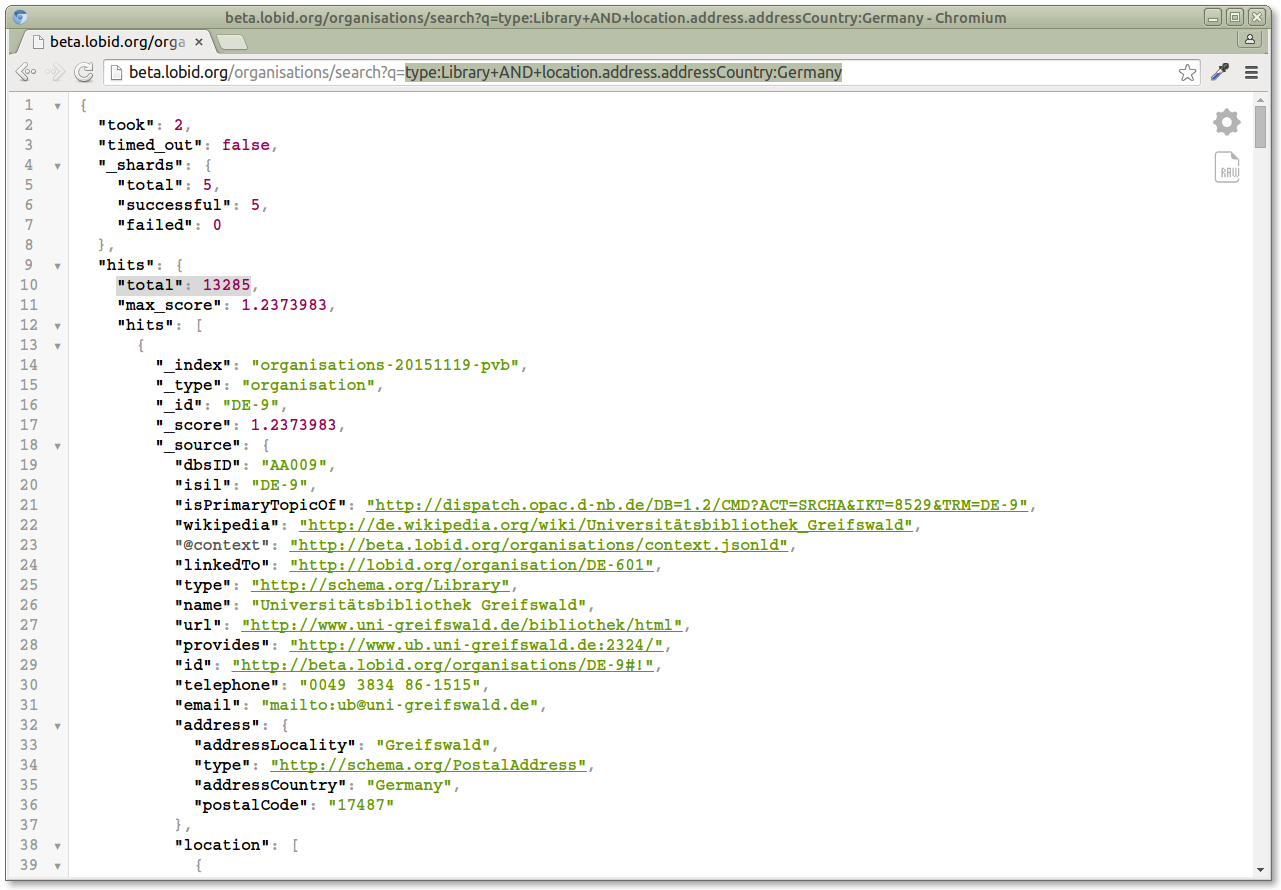 So that's the answer right there: there are 13.285 libraries in Germany, according to our data.
Now the initial result mentioned above said there are 19.347 libraries in Germany, this result now says 13.285. What about that? Well it's really that by using LOD for applications, by using the Lobid API, we were able to improve our query: while our data only contains German organisations, these are not necessarily in Germany, e.g. Goethe institutes. The initial query didn't consider that.
So that's the answer right there: there are 13.285 libraries in Germany, according to our data.
Now the initial result mentioned above said there are 19.347 libraries in Germany, this result now says 13.285. What about that? Well it's really that by using LOD for applications, by using the Lobid API, we were able to improve our query: while our data only contains German organisations, these are not necessarily in Germany, e.g. Goethe institutes. The initial query didn't consider that.
We were also able to improve our data. Because of course when your result is almost the double amout of the traditional answer you sanity check your results, and so we realized that we included organisations that were marked as inactive in our source data (see this issue for details). So we really saw here how usage leads to improvement.@lobidOrg @InspektorHicks Um genau zu sein: da sind auch Goethe Institute im Ausland mit dabei usw. Siehe http://t.co/wbpiGZl8OC
— dr0ide (@dr0ide) June 10, 2015
Application: visualize data on a map
Let's take a look at another application. Say we want to visualize data on a map, in particular the libraries in Hamburg. As a starting point, we take a query similar to the one above for answering how many libraries there are in Germany. Only in this case we don't use the "location.address.addressCountry" field, but the "location.address.addressLocality" field. If our goal would be to get the number of libraries in Hamburg we'd have the result right there, but in this case we want to do something with the result data. In particular, as we want to visualize the data on a map, we're interested in the "location.geo" field, which contains nested "lat" and "lon" fields, specifying the geo coordinates of each organisation: http://beta.lobid.org/organisations/search?q=type:Library+AND+location.address.addressLocality:Hamburg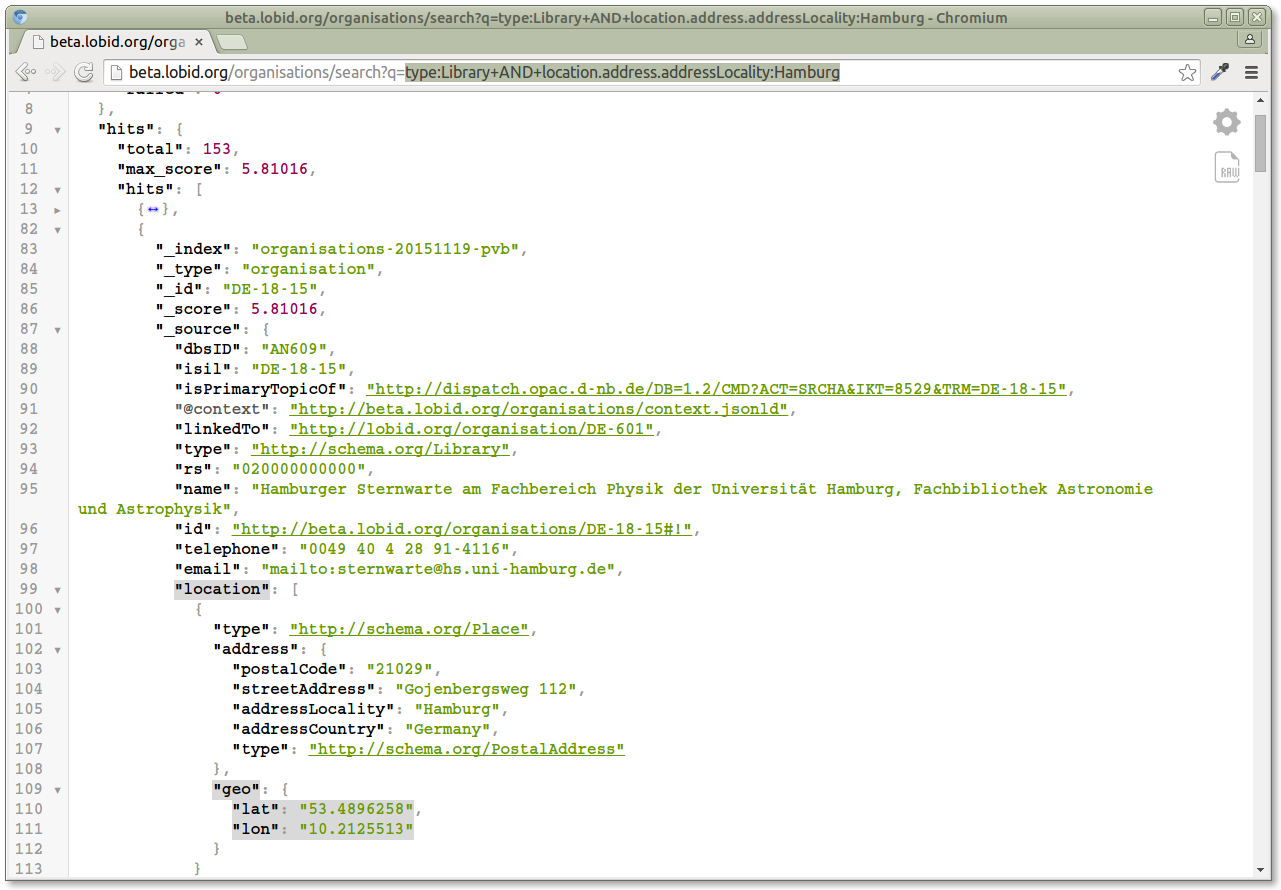 To use these in a map visualization, we create an HTML file in a text editor. In its head, we include a mapping package, leaflet.js. In the body, we create the map and add a tile layer to it. We then call the Lobid API with the very query from above, specifying that we're looking for organisations where "type:Library AND location.address.addressLocality:Hamburg". In the following lines we process the API response and finally create a marker for each organisation using the "location.geo.lat" and "location.geo.lon" fields:
https://github.com/hbz/slides/blob/swib-15/demo.html
To use these in a map visualization, we create an HTML file in a text editor. In its head, we include a mapping package, leaflet.js. In the body, we create the map and add a tile layer to it. We then call the Lobid API with the very query from above, specifying that we're looking for organisations where "type:Library AND location.address.addressLocality:Hamburg". In the following lines we process the API response and finally create a marker for each organisation using the "location.geo.lat" and "location.geo.lon" fields:
https://github.com/hbz/slides/blob/swib-15/demo.html
 If we open that HTML file in a browser, we get an interactive map with the libraries in Hamburg. We can zoom in and out, pan around, and click the markers for the name of the library:
http://hbz.github.io/slides/swib-15/demo.html
If we open that HTML file in a browser, we get an interactive map with the libraries in Hamburg. We can zoom in and out, pan around, and click the markers for the name of the library:
http://hbz.github.io/slides/swib-15/demo.html
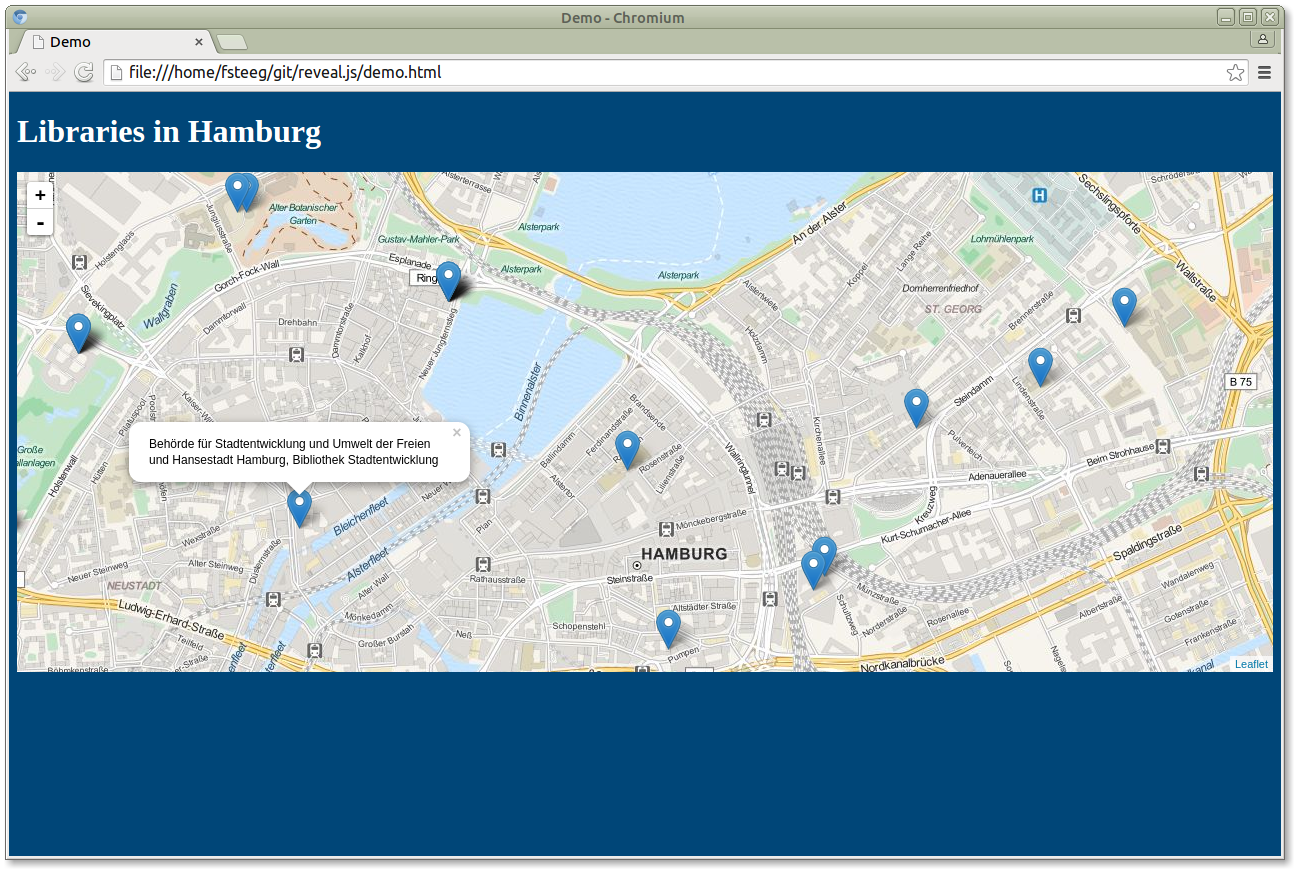 So that's how we can build an interactive map using the Lobid API.
So that's how we can build an interactive map using the Lobid API.
Application: NWBib
Next, let's take a look at a more complex application based on the Lobid API. NWBib is the regional bibliography for the German state North Rhine-Westfalia (NRW). It is catalogued by the three NRW-Landesbibliotheken, the federal state libraries (in NRW we don't have a single federal state library, but instead a distributed model). The presentation of NWBib is done by hbz, and its new version, currently in beta, is based entirely on the Lobid API. So let's take a look at NWBib. This is a details page for a book in NWBib: http://lobid.org/nwbib/HT016558942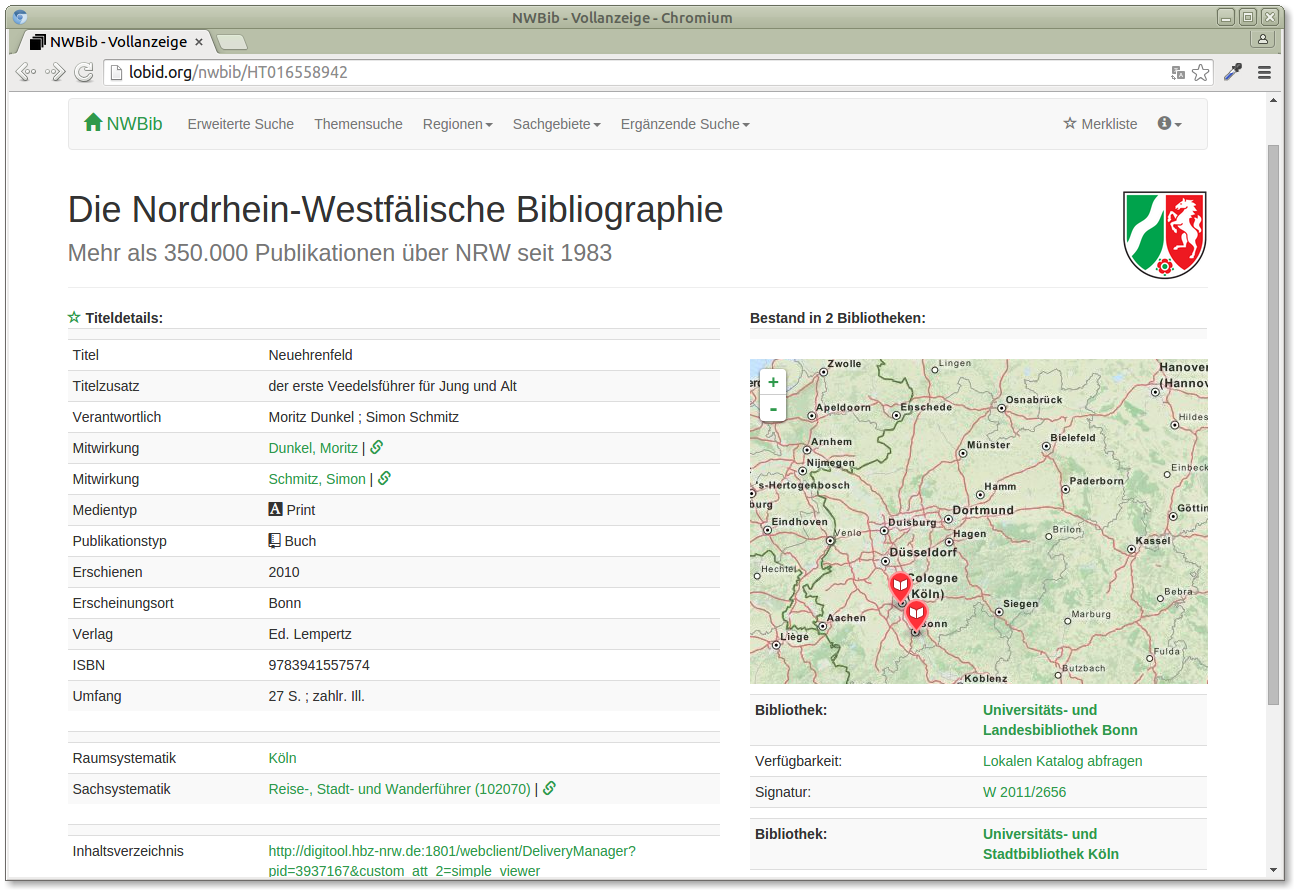 You'll notice the map on the right, with markers like in the previous sample application. It's basically done in the same way, only here it's not the libraries in some area, but libraries with holdings of the book this page is about.
It also provides some details when a marker is clicked, only here we zoom in, and provide links to the library, to a search for the holdings in the local library catalogue, and details on the holding's signature:
http://lobid.org/nwbib/HT016558942
You'll notice the map on the right, with markers like in the previous sample application. It's basically done in the same way, only here it's not the libraries in some area, but libraries with holdings of the book this page is about.
It also provides some details when a marker is clicked, only here we zoom in, and provide links to the library, to a search for the holdings in the local library catalogue, and details on the holding's signature:
http://lobid.org/nwbib/HT016558942
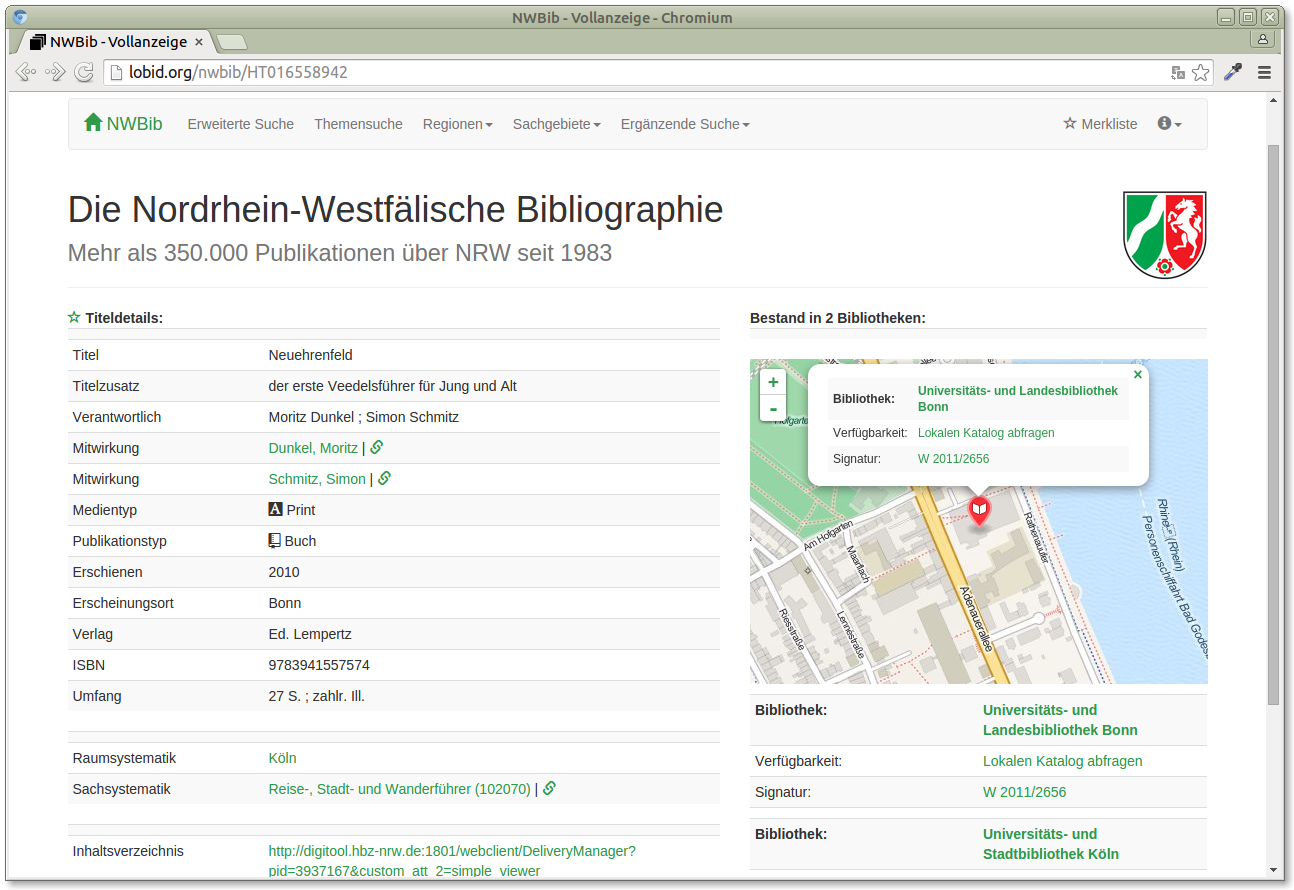 But again, it's basically the same thing as in the simple example above, just with some more work on the details.
Another interesting map related aspect of NWBib is that cataloguers always record a subject location, i.e. a place that a book or article is about. It is catalogued as a simple string, in the example above it's "Köln" (Cologne).
We take that string and send it to the Wikidata API, which returns a geo location. With these geo locations we can do multiple interesting things. For instance, on the NWBib landing page, we offer a location based search using the administrative districts of NRW:
http://lobid.org/nwbib
But again, it's basically the same thing as in the simple example above, just with some more work on the details.
Another interesting map related aspect of NWBib is that cataloguers always record a subject location, i.e. a place that a book or article is about. It is catalogued as a simple string, in the example above it's "Köln" (Cologne).
We take that string and send it to the Wikidata API, which returns a geo location. With these geo locations we can do multiple interesting things. For instance, on the NWBib landing page, we offer a location based search using the administrative districts of NRW:
http://lobid.org/nwbib
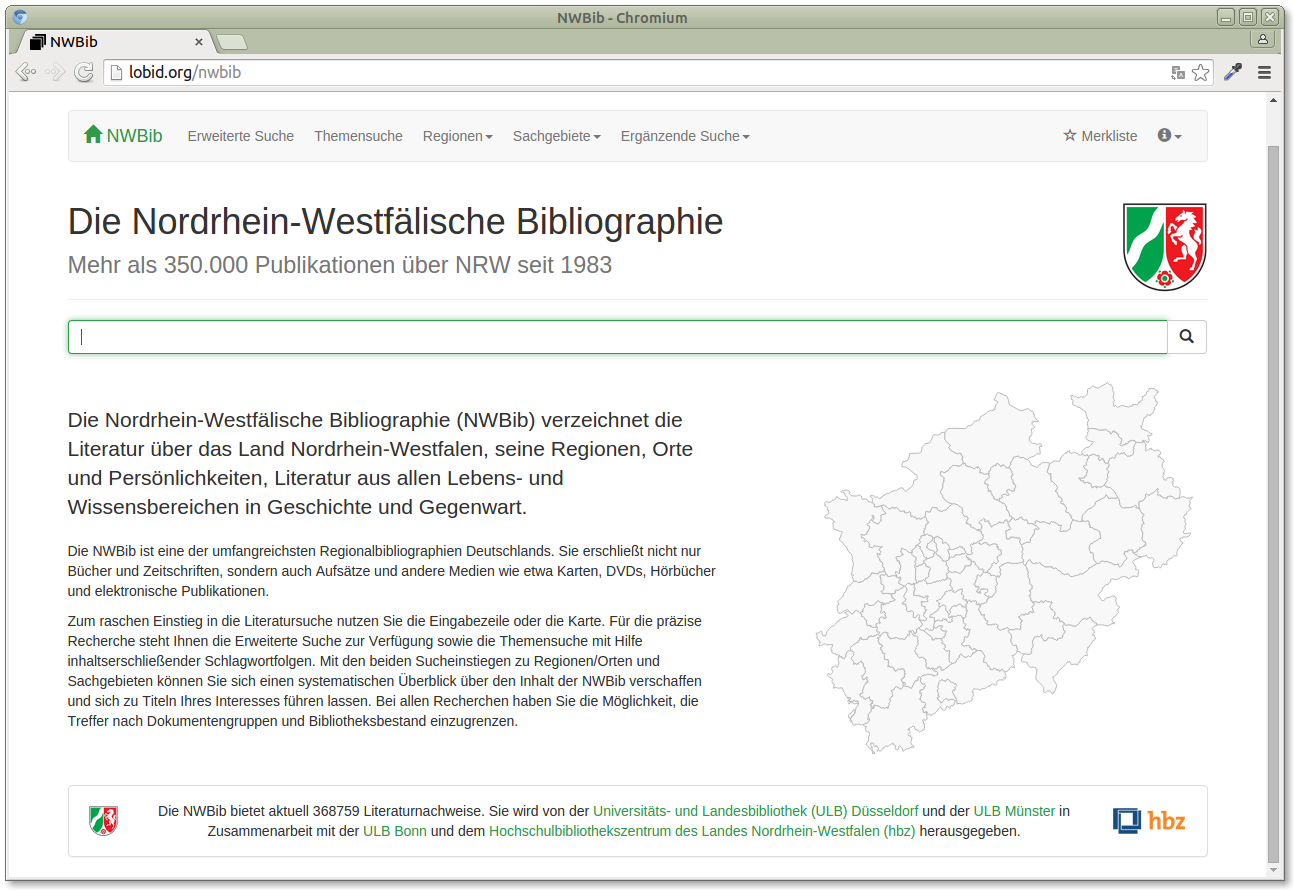 Clicking on one of these areas returns results related to places in that area.
Having these geo loacations also provides a way to visualize search results. For instance, if we search for "braunkohle" (brown coal or lignite) we see that there are two single places in the east of NRW related to that, but over 40 places in the west of NRW, the "Rheinische Braunkohlerevier":
http://lobid.org/nwbib/search?q=braunkohle
Clicking on one of these areas returns results related to places in that area.
Having these geo loacations also provides a way to visualize search results. For instance, if we search for "braunkohle" (brown coal or lignite) we see that there are two single places in the east of NRW related to that, but over 40 places in the west of NRW, the "Rheinische Braunkohlerevier":
http://lobid.org/nwbib/search?q=braunkohle
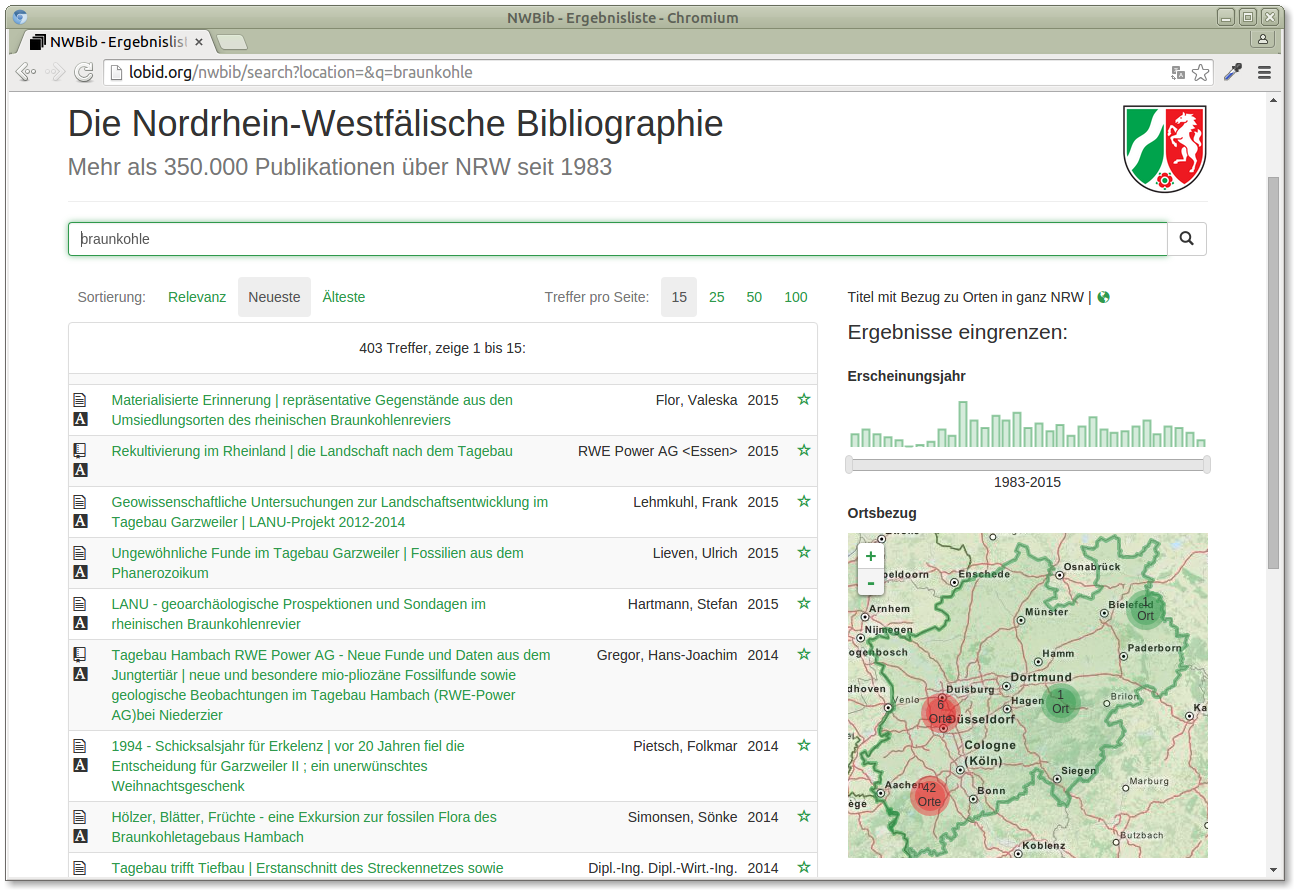 Again, the implementation is done basically the same way as in our simple example. Every place is a single marker, the clusters are created automatically using a plugin for the mapping package, Leaflet.markercluster.
The clusters can not only be used to visualize results, they can also be used for browsing. If we select a cluster, we can restict results to the search term and the selected area:
http://lobid.org/nwbib/search?location=...
Again, the implementation is done basically the same way as in our simple example. Every place is a single marker, the clusters are created automatically using a plugin for the mapping package, Leaflet.markercluster.
The clusters can not only be used to visualize results, they can also be used for browsing. If we select a cluster, we can restict results to the search term and the selected area:
http://lobid.org/nwbib/search?location=...
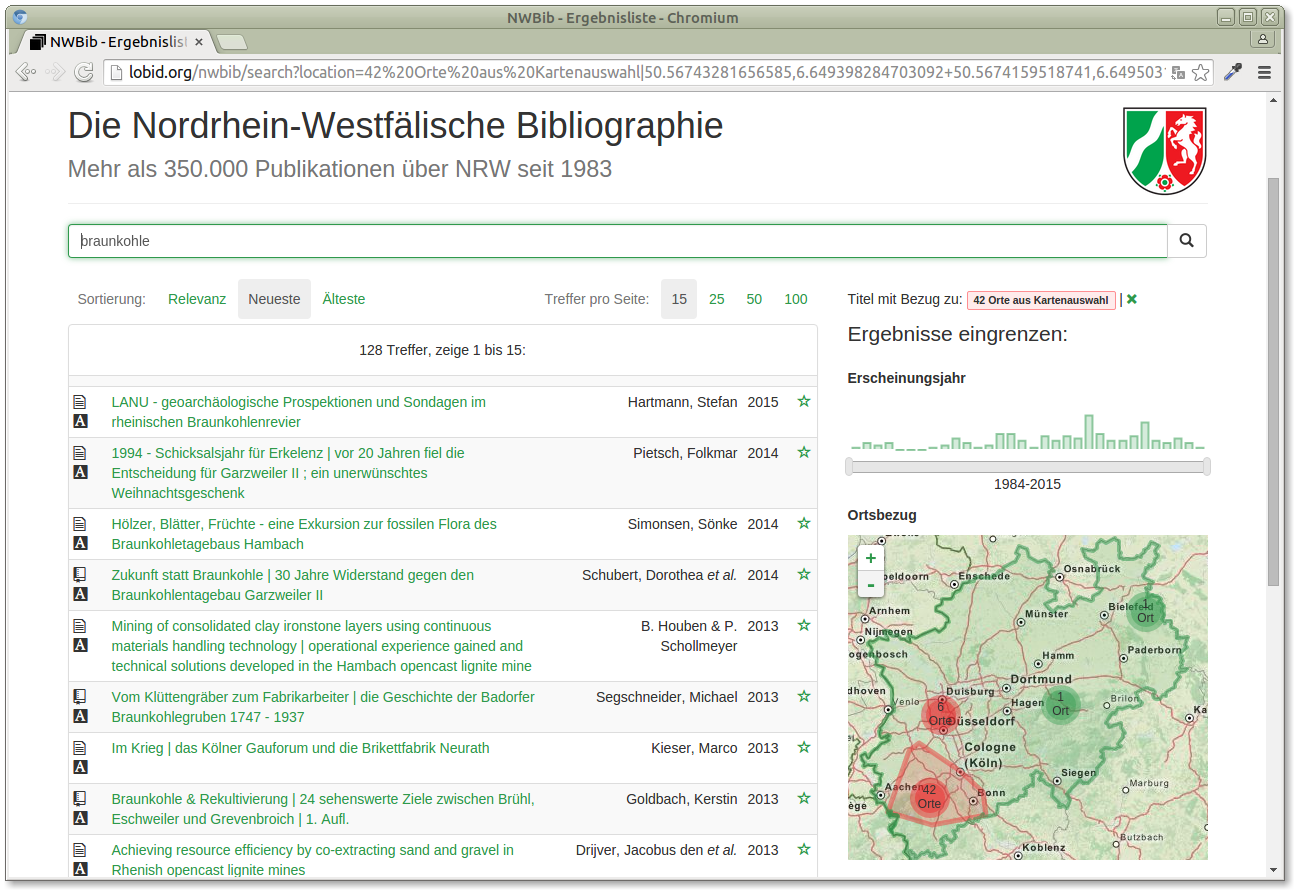 So that's how a complex application with map visualization and browsing can look like, implemented on top of the Lobid API, in the same basic way as the simple example above.
So that's how a complex application with map visualization and browsing can look like, implemented on top of the Lobid API, in the same basic way as the simple example above.
Application: OpenRefine
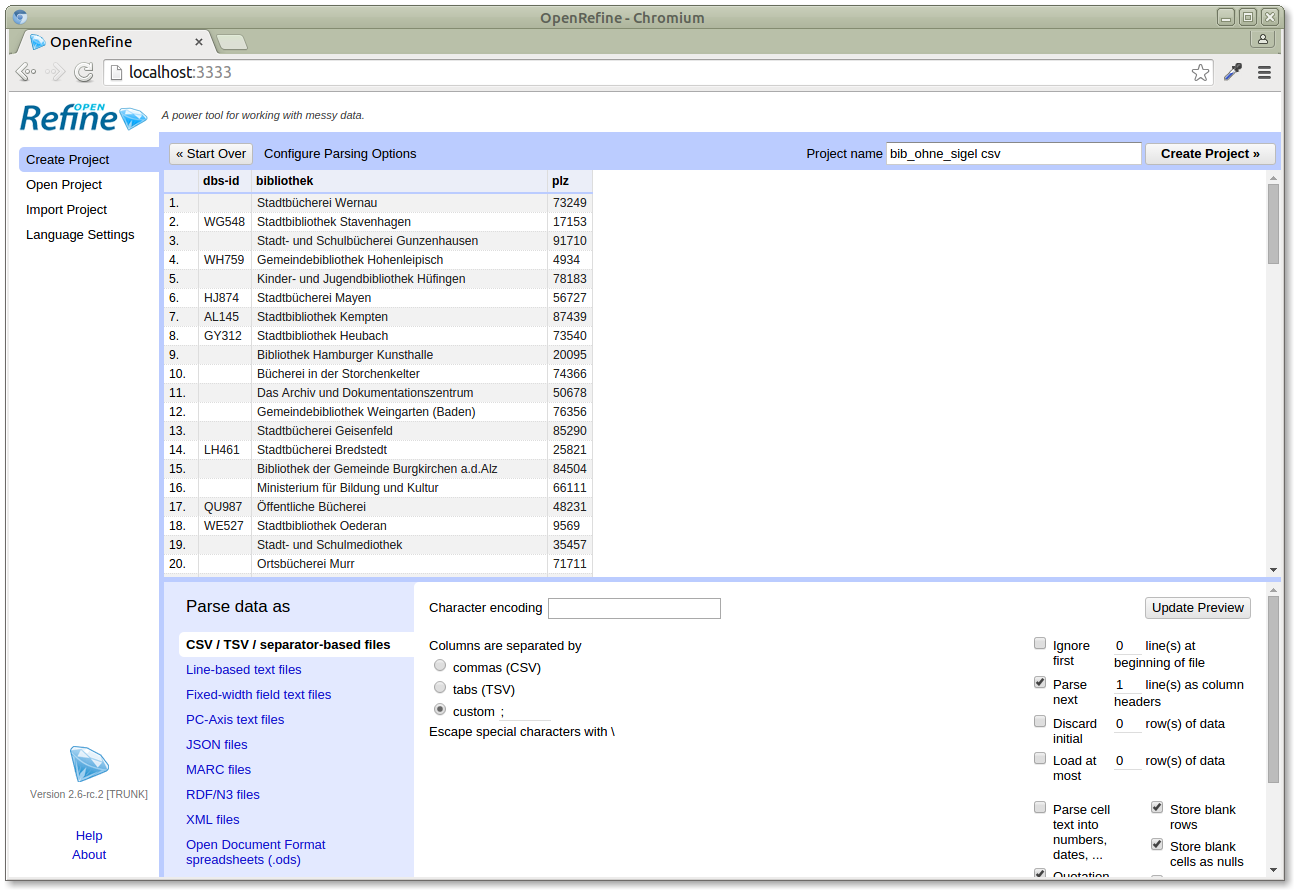
As a final application, let's take a look at OpenRefine, "a free, open source, power tool for working with messy data". OpenRefine is based on a spreadsheet user interface, so it provides a familiar user experience for people familiar with that kind of software. It can be used to clean up data, to transform data, and to reconcile data with external data sources, like the Lobid organisations API. We've implemented our OpenRefine reconciliation API in response to a user request, so let's take a look at that. Our user had a table of libraries where every row had a name and a postal code, and some had an ID from the German national library index (DBS, Deutsche Bibliotheksstatistik). What he wanted was a uniform identifier for all of these entries, in particular an International Standard Identifier for Libraries (ISIL), if available. OpenRefine uses the browser for its user interface. You can run it as a local application, it comes with simple executables for different operating systems. You don't have to upload your data anywhere, it just happens to be browser based. At the same time, this makes it possible to set up a central instance for your organisation and have people share projects and data. In its initial view, OpenRefine allows you to select the data you want to work with: Our data is a CSV file. After we load it, OpenRefine provides a preview of how it interprets the data and allows you to customize the way it is imported. As you can see in the "Parse data as" section, OpenRefine supports many different input formats. In our case it recognized the custom semicolon delimiter, and all default options are fine for us:
Our data is a CSV file. After we load it, OpenRefine provides a preview of how it interprets the data and allows you to customize the way it is imported. As you can see in the "Parse data as" section, OpenRefine supports many different input formats. In our case it recognized the custom semicolon delimiter, and all default options are fine for us:
 After we created the project, we get a simple tabular view of our data:
After we created the project, we get a simple tabular view of our data:
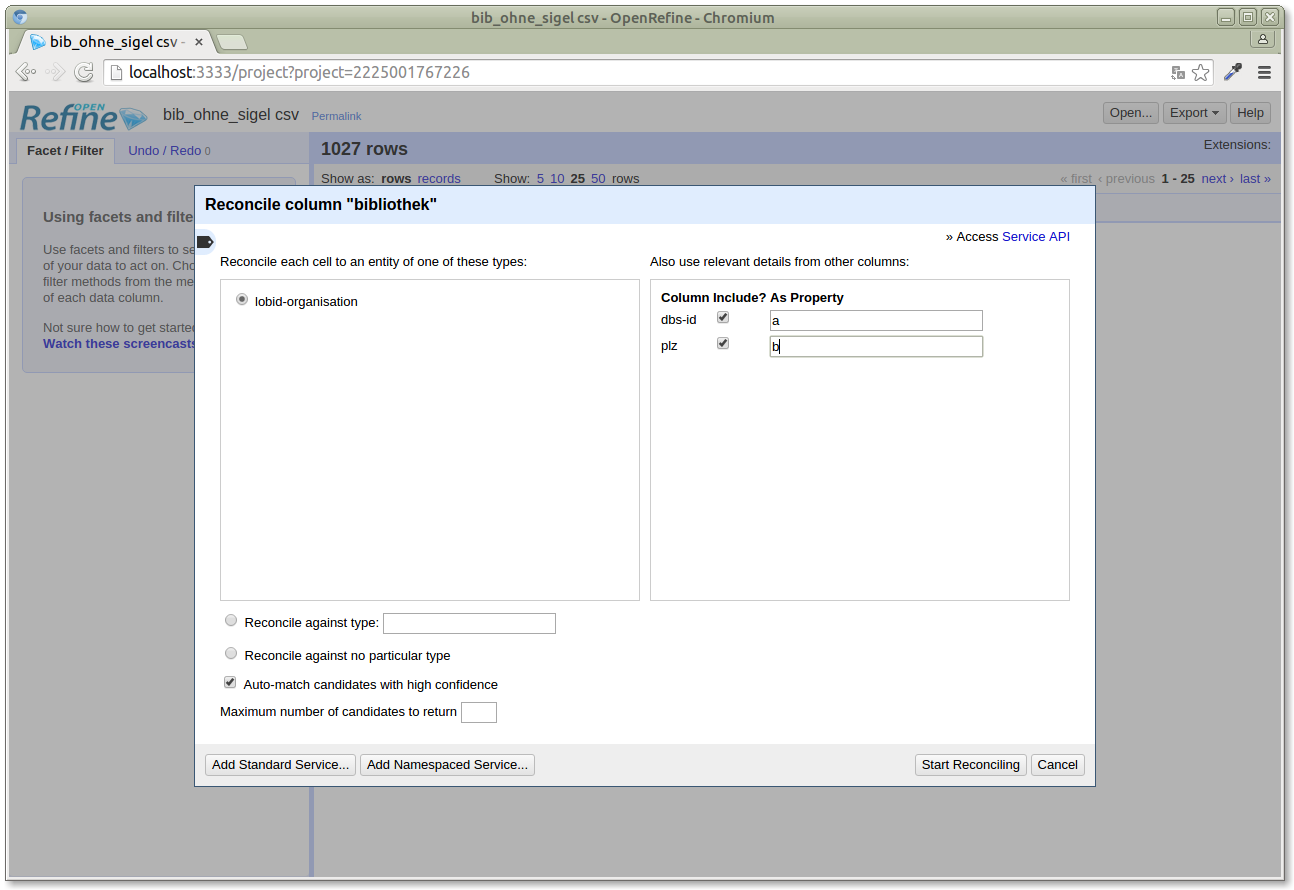
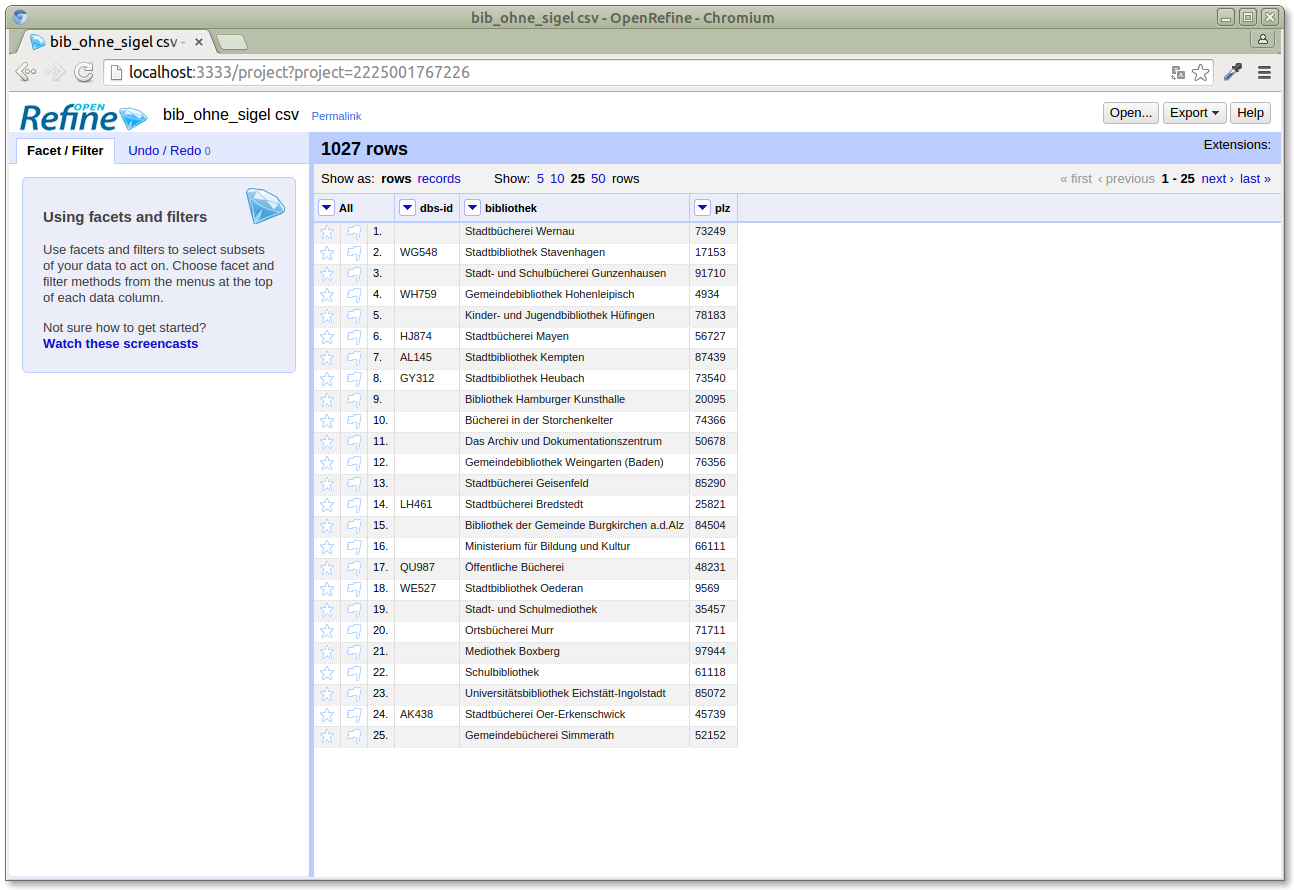 We'll now reconcile the "bibliothek" column, which contains the library names, with the Lobid API. We also pass the other fields (postal code and DBS ID) to the Lobid API to improve the result quality of the reconciliation candidates returned by the API (the "As property" values are arbitrary for the Lobid API, but need to be set):
We'll now reconcile the "bibliothek" column, which contains the library names, with the Lobid API. We also pass the other fields (postal code and DBS ID) to the Lobid API to improve the result quality of the reconciliation candidates returned by the API (the "As property" values are arbitrary for the Lobid API, but need to be set):
 After the reconciliation is done, i.e. every library in our table has been looked up in the Lobid organisations data, the Lobid API returns candidates for each library, ranked by their score, with the highest ranking candidate being the most likely match:
After the reconciliation is done, i.e. every library in our table has been looked up in the Lobid organisations data, the Lobid API returns candidates for each library, ranked by their score, with the highest ranking candidate being the most likely match:
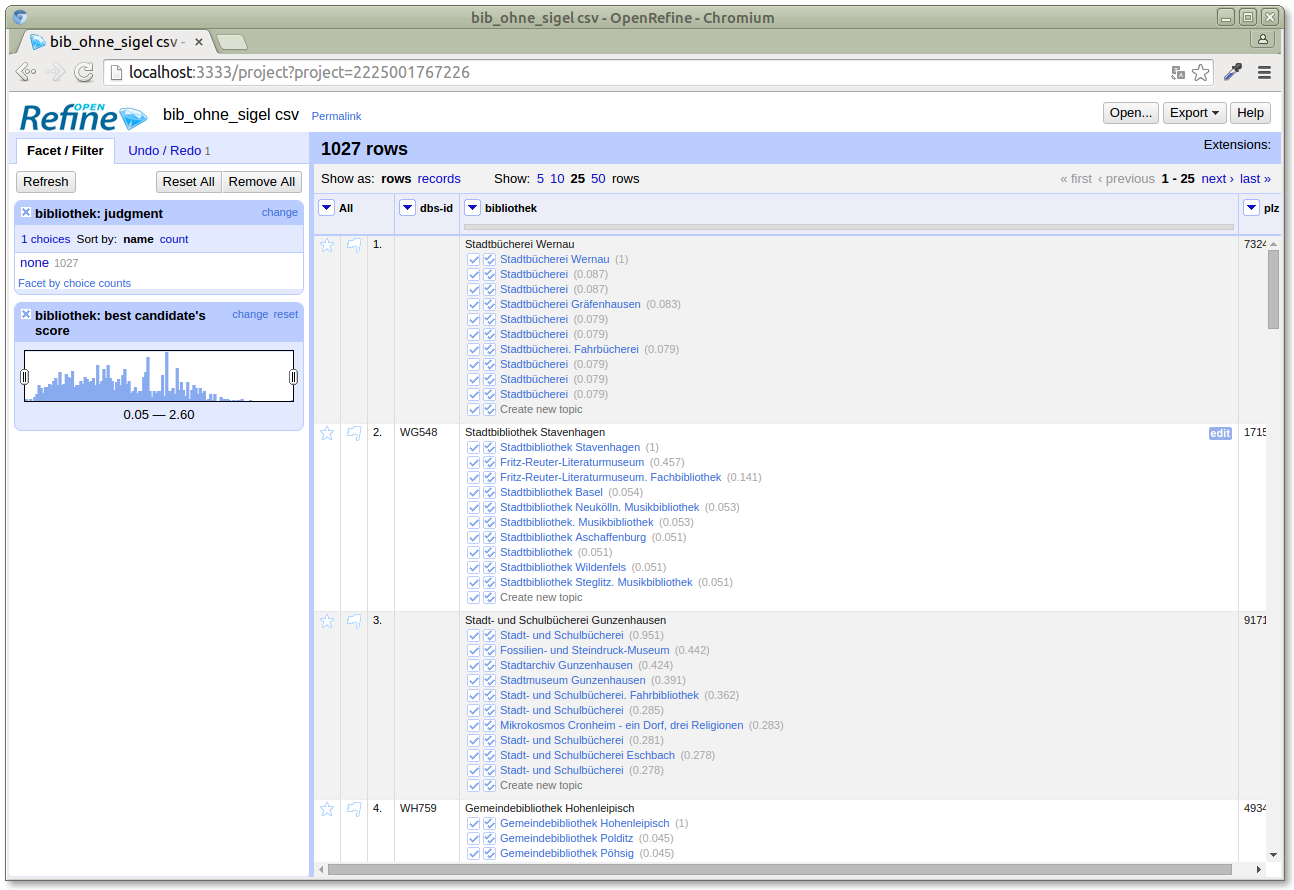 Each cell now contains a list of candidates. They are linked to their entries in the Lobid API, so by clicking them we can verify that the topmost candidate is actually a good match. The "best candidate's score" histogram facet on the left allows us to deselect libraries with very low scoring best candidates (by moving the left slider to the right), so we don't pollute our data with wrong matches.
The next step is to create a new column with the unified ID, based on the best reconciliation candidate. We use the OpenRefine expression language for that and create a new column called "hbz-id" (not all libraries have ISILs, the Lobid API returns something like pseudo-ISILs for these, so we don't call the column ISIL):
Each cell now contains a list of candidates. They are linked to their entries in the Lobid API, so by clicking them we can verify that the topmost candidate is actually a good match. The "best candidate's score" histogram facet on the left allows us to deselect libraries with very low scoring best candidates (by moving the left slider to the right), so we don't pollute our data with wrong matches.
The next step is to create a new column with the unified ID, based on the best reconciliation candidate. We use the OpenRefine expression language for that and create a new column called "hbz-id" (not all libraries have ISILs, the Lobid API returns something like pseudo-ISILs for these, so we don't call the column ISIL):
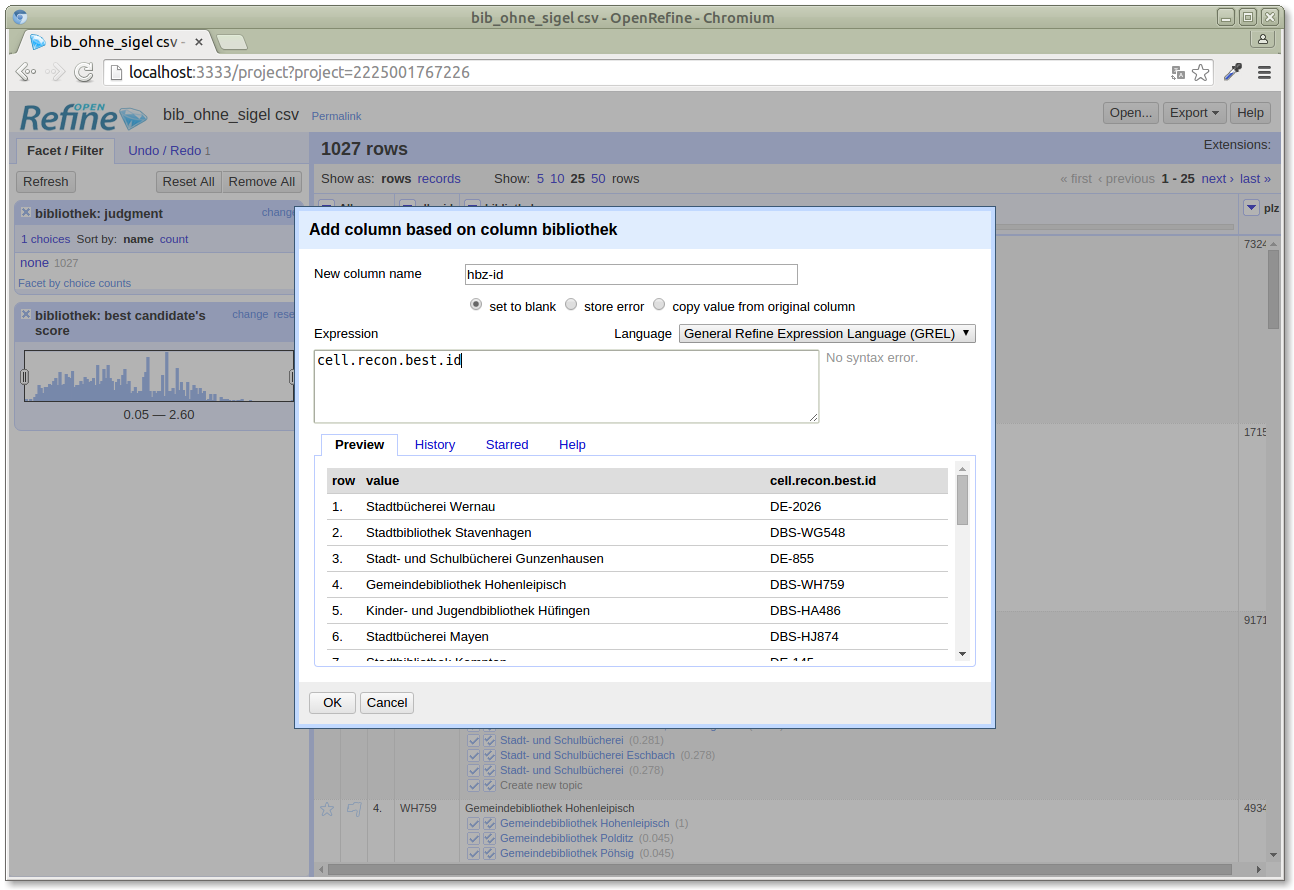 The expression we use, "cell.recon.best.id" means that for each cell, from its reconciliation result, pick the best candidate, and take its id as the value for the new column. The preview we see for that expression looks good, so we create the new column:
The expression we use, "cell.recon.best.id" means that for each cell, from its reconciliation result, pick the best candidate, and take its id as the value for the new column. The preview we see for that expression looks good, so we create the new column:
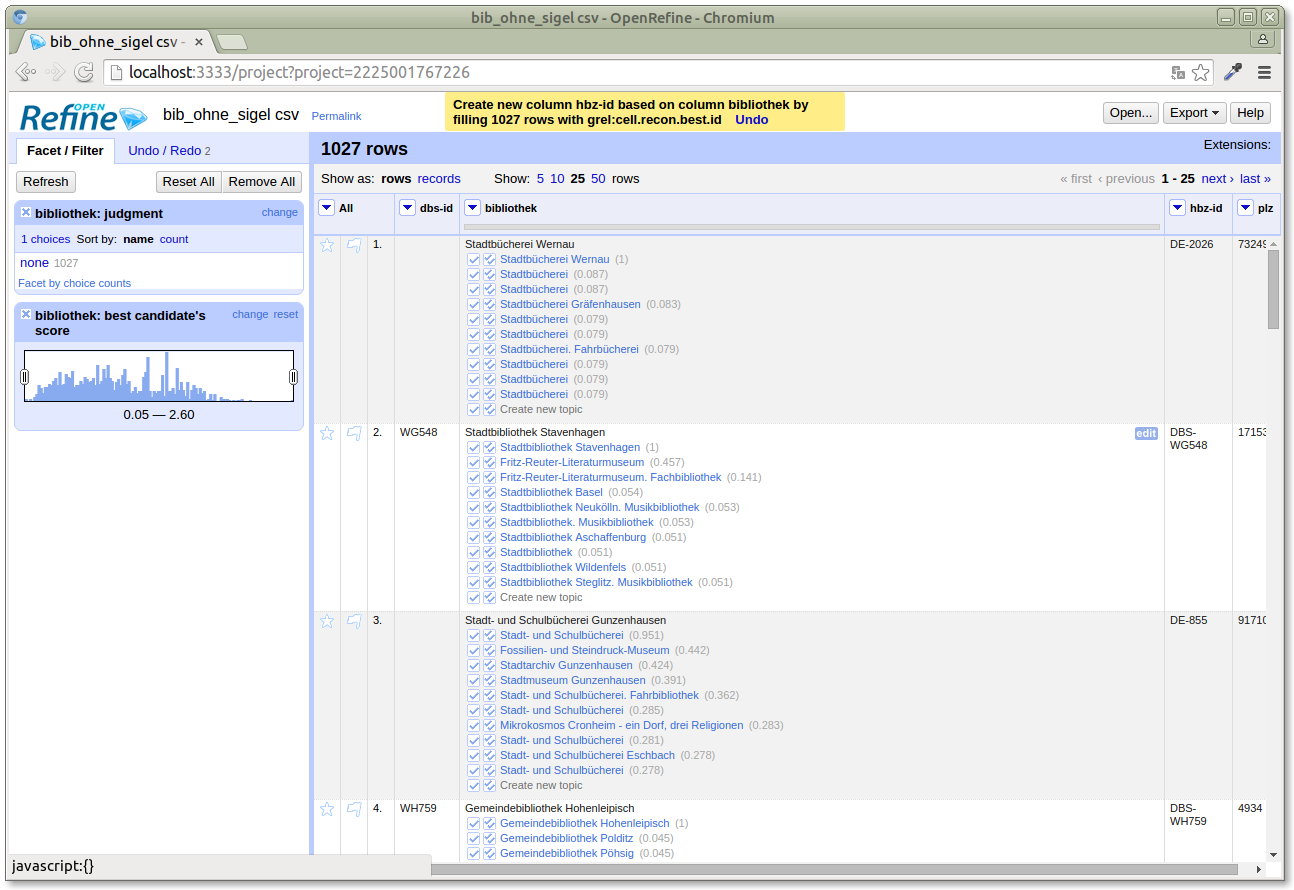 We could now export the resulting table with the new column as a CSV (or many other formats) to get the reconciled data set.
So this is what reconciliation with OpenRefine and the Lobid API looks like. You can download OpenRefine and reproduce these steps based on these instructions.
We could now export the resulting table with the new column as a CSV (or many other formats) to get the reconciled data set.
So this is what reconciliation with OpenRefine and the Lobid API looks like. You can download OpenRefine and reproduce these steps based on these instructions.
Lessons learned
So what did we learn by building and using the Lobid API and applications based on it? We learned that it's important not to lose useful data for applications in the transformation of source data to LOD. We learned that it's important to structure data in a way that makes it useful for applications, like for queries and processing responses. And we learned that if possible, we should integrate into existing tools and workflows like OpenRefine, because if people have these tools, that's where they want to use your data. To summarize, we learned to let applications drive API and data design. To avoid premature abstraction. To support actual use cases before generalizing. Or, to put it another way: "Do usable before reusable".And doing usable is great, because "having other folks use your stuff makes your stuff better!"Do usable before reusable.
— Einar W. Høst (@einarwh) August 21, 2015
So this is how we make progress: by building, using, and improving stuff. A short note on how we built our particular API: We used Metafacture (a Java toolkit for stream-based library metadata processing), Elasticsearch (a Lucene-based search server, something like SOLR, we use it with Java), and Playframework (a Web application framework, something like Rails or Django, we use it with Java). In a nutshell, that's Java programming with open source tools. But this is just our choice. An API like this could be implemented with all kinds of technologies. Now you might be wondering: but what about Linked Open Data (which is in this post's title), or even the Semantic Web (which is the topic of the conference I presented this as a talk)? For one thing, the structured data in all the examples above is JSON-LD, it is RDF compatible, we use standard vocabularies where possible, so this is linked data. But linked data and the semantic web are no goals in themselves. They are "a technological solution, one of many that might fit the real goals".@edsu Guess what - it turns out having other folks use your stuff makes your stuff better! Software and collections too!
— Andy Jackson (@anjacks0n) July 30, 2015
And no matter what our roles or titles are, whether we're cataloguers, developers, or managers, that real goal is the same: "to make the product better for our users".I'm so over linked data/semantic web as a goal. Its a technological solution, one of many that might fit the real goals/outcomes
— Euan Cochrane (@euanc) June 2, 2015
And that product is software. So what's the thing to take away? It's really that libraries, that we, that you, should build APIs. APIs provide infrastructure for software in libraries. They make the great work of cataloguers available for all kinds of use cases. That's why "libraries need APIs"."No matter what our job titles, our jobs are all the same — to make the product better for our users." http://t.co/Rz8CnWvlbm
— Fabian Steeg (@fsteeg) February 25, 2015
They empower yourself and others: to use your data (as we saw in the simple question answering example), to build new applications (as we saw in the simple and complex map-based applications), and to improve existing applications (as we saw in the OpenRefine example). It doesn't happen by itself. It's not like you build an API and all these applications magically appear. What it takes is "an API and some large-but-finite amount of labor"..@fsteeg Yep. Libraries need APIs, not web portals.
— Ralf Claussnitzer (@claussni) July 29, 2015
But APIs are the foundation. They provide infrastructure for software in libraries. They empower yourself and others.Realizing that I say "it wouldn't be difficult to X" when I mean "there's an API and some large-but-finite amount of labor could X."
— Ted Underwood (@Ted_Underwood) September 2, 2015